Open Source · Local-Model Fork
goose local edition
A fork of the open-source goose agent that turns a fleet of small local models into a self-verifying coding swarm — decompose a spec into a task DAG, build it in parallel, and prove it works by running it.


Runs Fully Local Multi-Agent Swarm Judged by Running
100%
on-device, zero cloud
330+
commits and counting
20+
swarm features, all flagged
5
layered verification gates
What goose local edition is
goose is the open-source coding agent originally created by Block (the company behind Square and Cash App) and now stewarded by the Agentic AI Foundation at the Linux Foundation. Upstream, it drives a single capable model. goose local edition assumes the opposite premise — many weak models, running on hardware you already own — and builds the orchestration that makes that work.
The wager is simple. A single 27-billion-parameter model cannot match a frontier model, but its real weakness is not writing code — it is wiring modules together and knowing when it is actually done. So the leverage is not a better model; it is coordination and verification. The swarm decomposes a spec into a dependency graph of subtasks, farms them across the fleet, and — the doctrine the whole project rests on — verifies the result by running it, never by a green test count.
The target is the failure class that kills naive multi-agent builds: apps that compile and pass their unit tests but crash the moment you run them end-to-end, because parallel workers drifted on a shared interface no isolated test ever exercised. Almost every feature below exists to close that gap — before the code is written (contracts), while it is written (the judge), and after (the gates) — on a machine where no code ever leaves your network.
It is a research fork, not a polished product: actively developed, honest about its limits, and measured empirically by a self-driving test harness rather than by claims.
Why Fork goose for Local Models?
Cloud tooling is tuned for one strong model. A local fleet is a genuinely different problem — and that is the whole point.
Weak, but Plural
A single small model can't match a frontier model. But a fleet of them, coordinated, can. The swarm turns several local models into a parallel coding team that decomposes and builds real software.
Different Orchestration
Cloud tooling assumes one strong model. Local fleets need work-stealing scheduling, frozen interface contracts, and verification a weak model can't fake by claiming 'done'. That is exactly what this fork adds.
Privacy, Cost, and Control
Everything runs on hardware you own, through LM Studio. No API bills, no code leaving your network, and full control over which models run and how the loop behaves.
How the Swarm Works
One spec becomes a fleet of parallel subtasks and, if the gates pass, a program that actually runs — SCOUT to VERIFY.

1
Scout
Fixed-lens scouts investigate the problem in parallel across the fleet — libraries, edge cases, architecture — so planning starts from real information.
2
Plan
The smart model drafts several skeleton plans at once, and a deterministic scorer picks the widest, flattest task DAG — the most work that can run in parallel.
3
Execute
A work-stealing scheduler farms subtasks across the fleet, routes hard work to the fastest node, and re-routes a stalled worker without killing honest slow work.
4
Verify
Smoke, an AST reviewer, and an end-to-end sink grade the app by running it — re-dispatching a targeted fix for whatever they find.
Every Knob, and Why It Exists
The full feature set, grouped by phase. Every one is a runtime flag, default-off so upstream builds stay byte-identical — and every one exists because a benchmarked app broke without it. Expand a group to read the details.
- Parallel research scoutsdefault on — Fixed-lens scouts (libraries, edge cases, architecture) investigate in parallel across the fleet instead of the planner scoping serially; their findings are injected into every later worker prompt.
- Best-of-N skeleton planning — The smart model drafts several skeleton DAGs at once and a pure-Rust scorer picks the widest, flattest, least-conflicting one — using the same graph loader the executor uses, so planner and executor can never disagree.
- Fleet detailing — Every terse subtask is expanded into an implementation-ready spec in parallel, each detailer handed the subtask's exact owned filenames so it can't invent a contradicting path that dooms the worker.
- Plan confidence — A pure-Rust self-consistency score across the N drafts (weighted 0.7) blended with a deliberately harsh verbalized self-rating (0.3), because a model's own confidence number is systematically overconfident.
The Model You Load Matters Most
A controlled A/B pitted qwen3.6-27b vanilla (the official lmstudio-community build) against the community qwopus3.6-27b coder variant — same specs, same frozen binary, only the model changed.
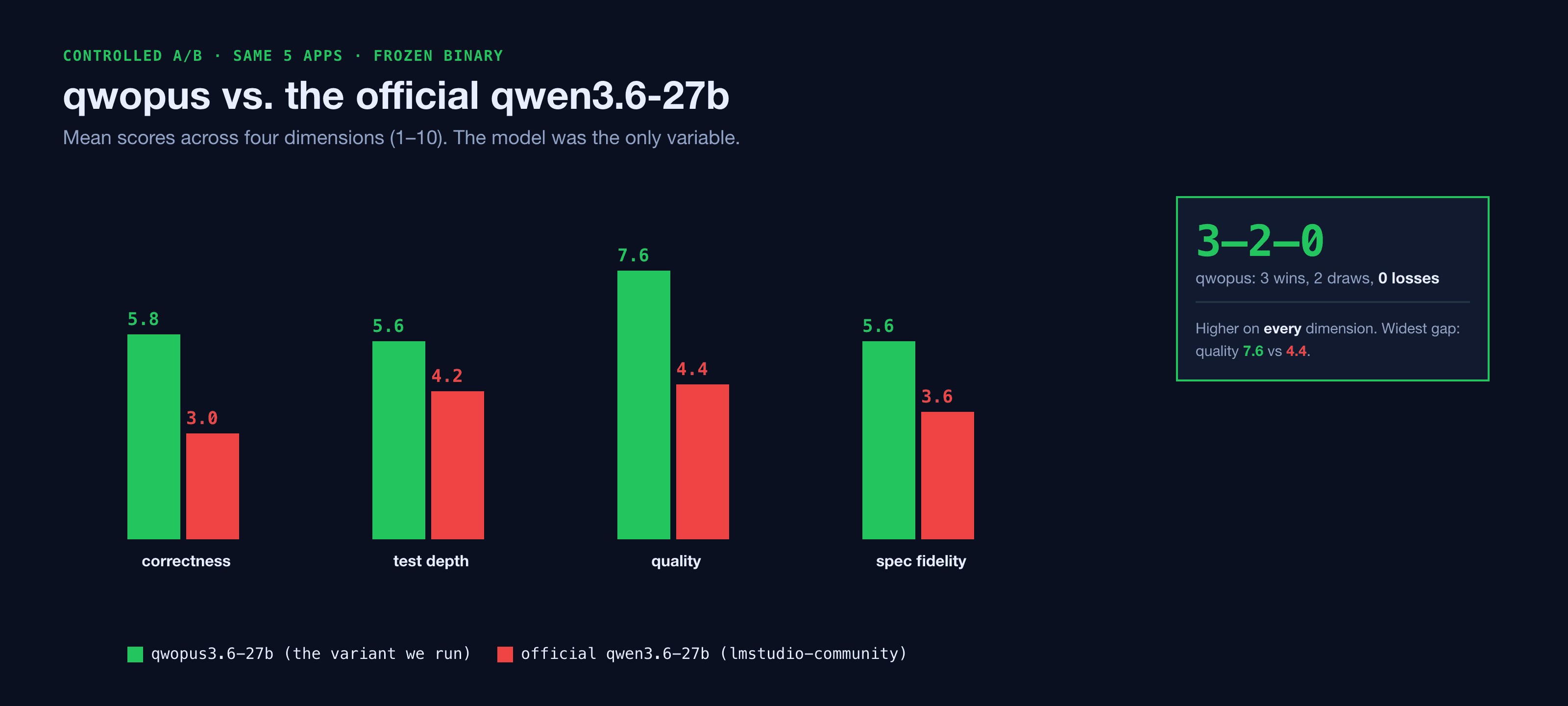
The qwopus variant won 3–2–0 and scored higher on every dimension. On one app vanilla qwen wired a corrupted default while the correct code sat unused; on another it shipped a dead, duplicated module that running the app, the unit tests, and a human review all missed — only the swarm's deterministic reviewer caught it. For local agentic coding, the specific model you load can matter more than any orchestration on top of it — so the fleet runs qwopus.
The Machinery at a Glance
The six pillars that get correct, runnable software out of a fleet of unreliable workers.
Task-DAG Swarm
Decomposes a spec into a validated dependency graph — cycle-checked at load time — and runs it in parallel, starting the tasks that unblock the most downstream work first.
Work-Stealing Scheduler
The least-loaded node wins, the hardest tasks route to the fastest host, and a genuinely stalled worker is re-routed — while an honest slow task runs untouched.
Interface Contracts
Signature-only stubs and exact database schemas are frozen before anyone writes code and injected into every worker, so parallel modules can't drift apart.
Model-Free Judge
Catches a worker that explores forever or claims 'done' without writing a file by counting actions, not reading tokens — so a weak judge can never cut a healthy worker.
Judged by Running
The smoke gate runs the generated tests, an AST reviewer flags built-but-unwired modules, and a final sink runs the app on real input. A green test count is never enough.
Self-Driving Harness
swarm-gym invents tasks, drives them through the swarm like a real user, and grades by execution — so every improvement is measured against real runs, not guessed.
Judged by Running, Not by "PASS"
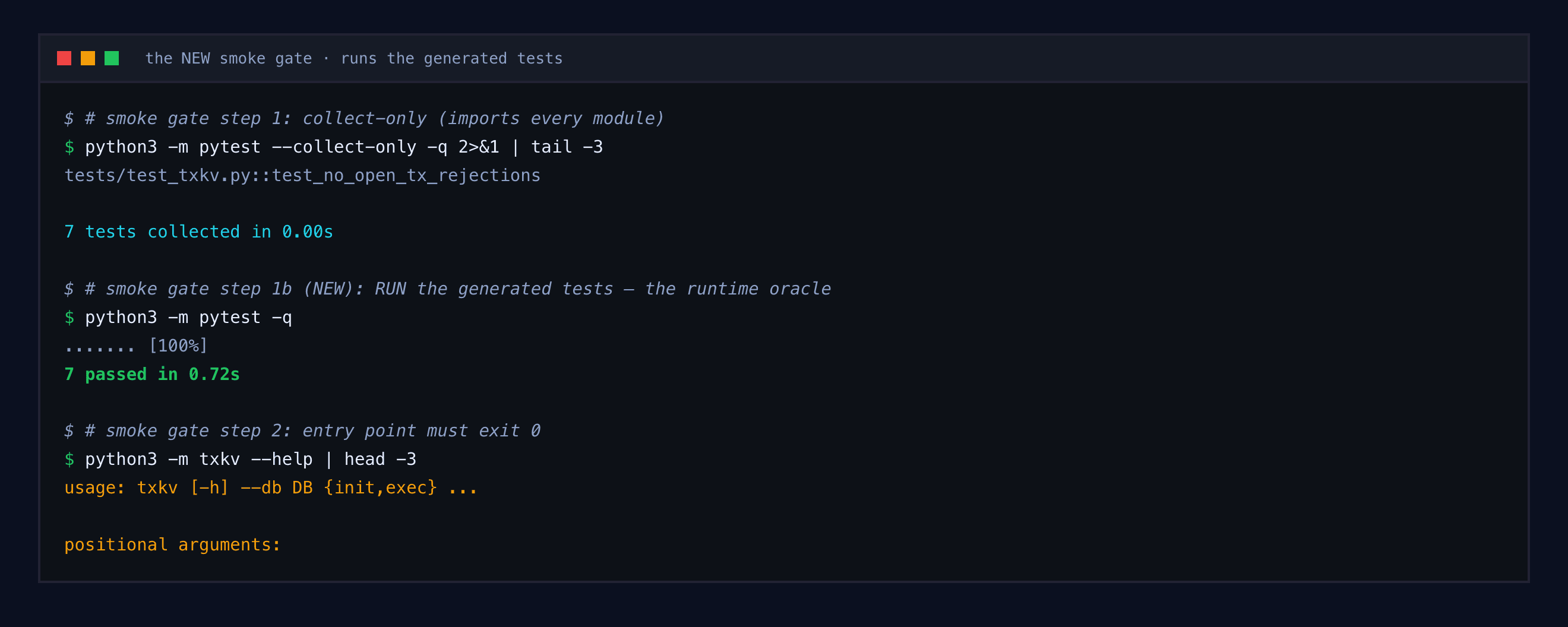
A weak model will cheerfully write forty-five tests that all pass while the real program crashes on the first realistic input. So the verification is adversarial and deterministic: it runs the binary.
The smoke gate imports every module, then actually runs the generated test suite, then checks the entry point — and each oracle is inconclusive, never a false red, on a missing tool. A final end-to-end sink builds and runs the advertised entry on the spec's exact commands with a golden-value check.
Fleet Size & the Sweet Spot
The swarm was benchmarked on a small LAN — but that is a test rig, not a ceiling. The scheduler is work-stealing, so it scales to as many nodes as you point at it.
Scales by Adding Hosts
Because the scheduler steals work to the least-loaded node, adding machines adds parallel throughput with no code change. Keep one resident model per host (weight 1) — scale out with more hosts, not more models per box, to avoid RAM and model-load thrashing.
Bounded by Plan Width
A single app can only parallelize as wide as its plan. The planner produces roughly two-to-three times the worker count in cohesive subtasks with shallow dependencies, and the first wave runs as wide as the fleet — so extra nodes pay off up to that width, which grows with the app's complexity.
One Coordination Point
The skeleton is drafted best-of-N across the fleet but converges on a single plan, and the final integrate-verify sink is one task. Those are the two serial moments; everything between them fans out.
The sweet spot
For a typical single app spec, a handful of 27B-class machines on a LAN — roughly three to six — captures most of the parallelism, since that is about as wide as a plan for one app usefully gets. Bigger, more decomposable specs (or running several apps at once) are where larger fleets earn their keep. The controlled A/B above ran on a three-node rig of Apple Silicon Macs over LM Studio; scale beyond that follows the architecture but has not been benchmarked yet — stated plainly rather than promised.
A Harness That Drives Itself
swarm-gym is two LLM layers: a smart brain invents and grades tasks, while the local fleet does the building — so every change is measured against real runs.
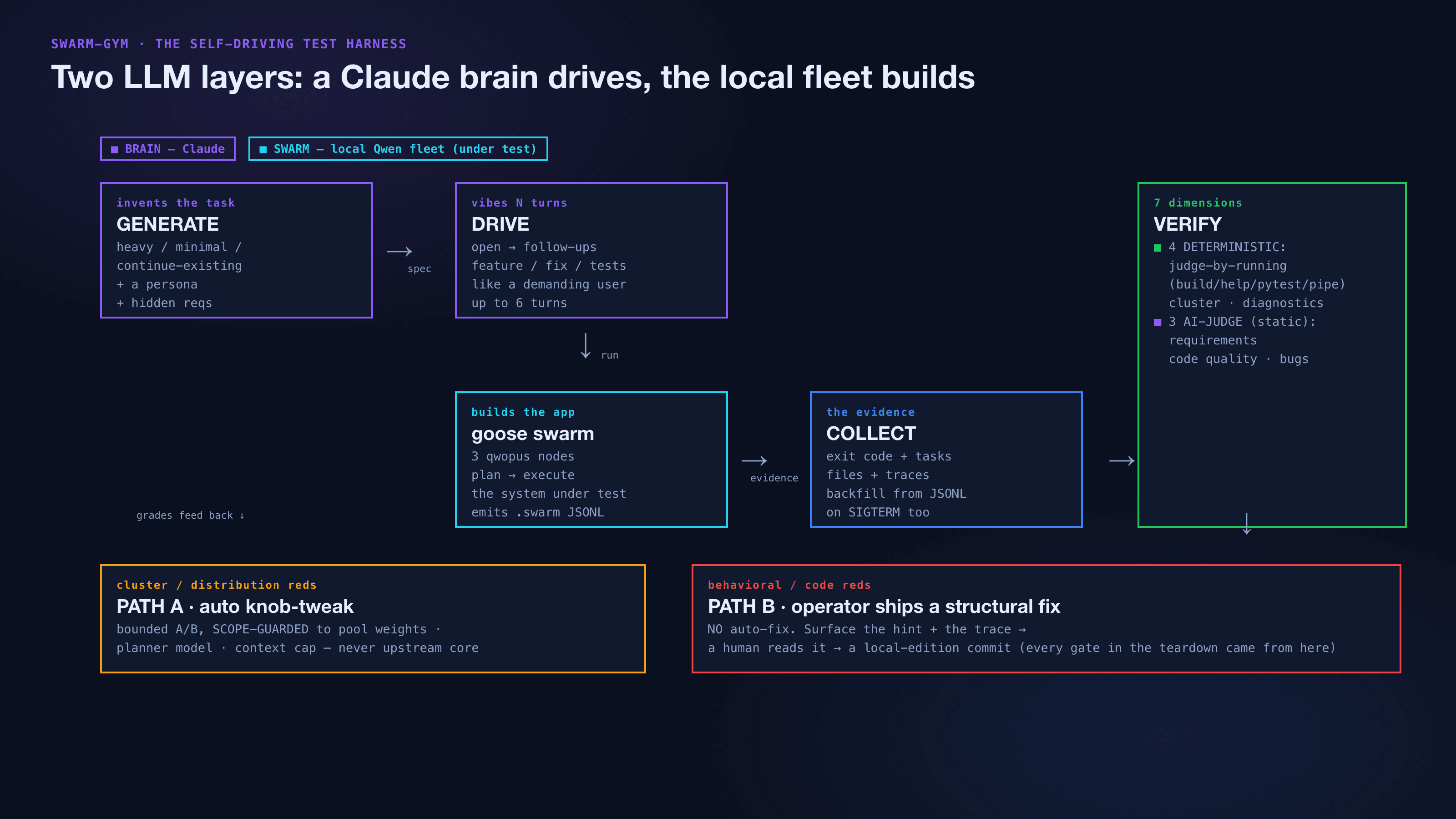
The brain invents a task, drives it through the swarm across several "vibing" turns like a real user, and grades on seven dimensions — but only three come from the AI judge. The other four are deterministic, and the real grade is execution. Cluster problems auto-tune a safe knob; behavioral problems send a human to read the trace and ship a structural fix.
Honest About the Limits
This is a research fork, not a polished product. Here is what it does well today and where a small local model still hits a wall.
Where It's Strong
- Multi-module CRUD across formats, with round-trips and aggregation
- Recursive-descent parsers and real compute — precedence, no eval()
- Nested transactional logic, verified by running
- Interface-drift-free builds via frozen contracts
- Every win confirmed by executing the app, not a green suite
Where It's Still Weak
- Recursive-algorithm cores at cumulative complexity
- Cross-module data-shape consistency on the hardest apps
- Weak-model self-repair of subtle runtime bugs
- Raw wall-clock speed on multi-module builds
These are weak-model capability limits, not swarm-coordination gaps — and we log them honestly rather than hiding them behind a green scoreboard.


Actively Developed & Supported
Built for Local Models — and Still Evolving
goose local edition is an open fork we keep pushing forward — sharper scheduling, new verification gates, and regular ingests from upstream goose. It is built specifically for local-model usage, and we support it in the open.
Clone it, point it at your own LM Studio fleet, and tell us what breaks. Contributions and war stories welcome.